【俺的理解】ブラウザのレンダリングの仕組み
公開日:
【俺的理解】シリーズは、自分が調べた内容を噛み砕いて、実際に試してみたり、まとめたりした記事です。 全力で調べて、自分が納得したことしか書きませんが、万が一間違っていることがありましたら twitter などで指摘していただけるとありがたいです。
はじめに

正月に実家に帰って、妹に 『フロントエンドエンジニアなのに、ブラウザの仕組み理解してないってマ!?』 と煽られたので、まとめました。嘘です。 『Web フロントエンドハイパフォーマンスチューニング』 という本の最初に、ブラウザの仕組みという章があってとても興味深かったので、この本の内容と少し調べたことを自分なりにまとめました。
概要
ブラウザは web サイトを閲覧するためのソフトウェアでいくつかのソフトウェアコンポーネントから構成されていますが、この記事では
- レンダリングエンジン
- JavaScript エンジン
に着目して、描画の流れをまとめていきます。
レンダリングエンジンは HTML や画像ファイル、CSS ファイルや JS ファイルなどを読み取って画面上にピクセルとして表示することを担当するもので、JavaScript エンジンは JavaScript の実行環境を提供するものです。
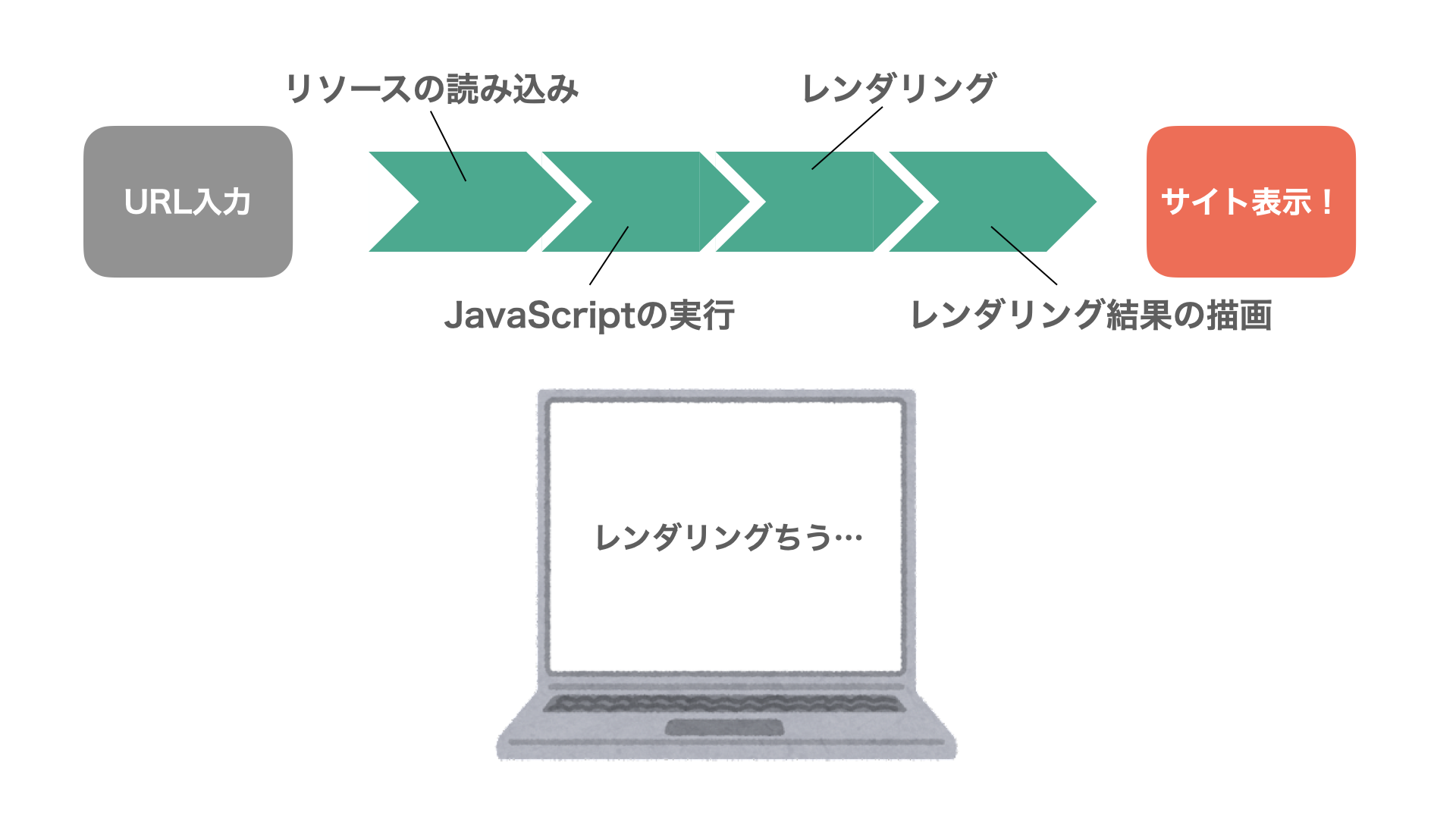
描画までの大まかな流れ
- リソースの読み込み
- ダウンロード
- 変換
- JavaScript 実行
- レンダリング
- スタイルの計算
- レイアウト
- レンダリング結果の描画
- グラフィックエンジンに向けた命令の作成
- 命令の実行
- レイヤーの合成
1.リソースの読み込み
リソースの読み込みのフェーズでは
- リソースのダウンロード
- リソースの変換
の 2 つを行います。
リソースのダウンロード
まずは表示するために必要なリソースを HTTP 経由でサーバーから読み込みます。ここでのリソースというのは以下のファイルのことを指します。
- HTML ファイル
- CSS ファイル
- JavaScript ファイル
- 画像ファイルや動画ファイル
まず、HTML ファイルをダウンロード。そして、その中で参照されている CSS ファイルなどを続いてダウンロード、さらにその中で参照されいてるファイル…というように再起的にファイルをダウンロードします。
リソースの変換
ブラウザは HTML をそのまま解釈できるわけではありません、つまり自分が解釈できるように HTML を変換する必要があります。その、解釈できる形というのが DOM(Document Object Model) と呼ばれるものです。 HTML ⇒ DOM への変換は以下のような順序で行われます。
- 字句解析によるトークンのリスト化
- 構文解析による構文木の構築
この流れをわかりやすくしたのが下の図です

https://web.dev/critical-rendering-path-constructing-the-object-model/
流れを見ていきましょう。
字句解析によるトークンのリスト化
トークンをリスト化するというのは、画像で言うところの 『Characters ⇒ Tokens』 の部分です。Characters が HTML 形式でマークアップされたテキストで、そのテキストがレンダリングエンジンによって、<html>や<body>などの意味を持つ 1 つの文字の塊、すなわちトークンに切り分けられ、並べられていきます。
そして、トークンはオブジェクトに変換されその中で特性やルールが定められます。これは、画像で言うところの 『Tokens ⇒ Nodes』 の部分であり、ここでできたオブジェクトのことをノードと言います。
構文解析による構文木の構築
最後に、親子関係を加味しながらノードを組み合わせていきます。この過程で最終的に出来上がるのが DOM(Document Object Model) です。ノード の中に、<img src=’img/logo.png’>などのリソースが存在する場合は、読み込まれながら DOM が生成されていきます。
CSS の変換
HTML の head タグなどに、スタイルシートの link タグがあった場合、CSS ファイルが読み込まれることになります。HTML 同様、CSS もブラウザは直接解釈することができません:sob:。なので、HTML と同じの順序で CSS も CSSOM(CSS Object Model) に変換する必要があります。
2.JavaScript の実行
レンダリングエンジンは HTML の解析中に script タグを見つけるたびに、コードを JavaScript エンジンに引き渡し、同期的に JavaScript を実行します。
実行の流れ
- 字句解析
- 構文解析
- コンパイル
- 実行
字句解析
JavaScript を実行するためには、機械が解釈できるように機械語に翻訳する必要があります。そのために、まずは構文木を作成します。構文木を作成するために、HTML でも行ったように、字句解析をして意味のある文字の塊(トークン)にコードを分割します。
構文解析

字句解析の結果得られたものを構文解析し、抽象構文木というものを作成します。これでやっと JavaScript をコンパイルする準備がでできました。
コンパイル
構文解析で得られて抽象構文木をコンパイルして機械が解釈できる 01 の羅列の機械語に変換します。この変換をコンパイルと呼びます。どのようなやり方でコンパイルが行われるかは、ブラウザの JavaScript エンジンに依存していますが、多いのは JIT コンパイル型と呼ばれるものらしいです。詳細は下の記事がわかりやすかったので、気になる方は読んでみてください。
https://devsakaso.com/javascript-about-just-in-time-compiler/
実行
コンパイルされたタイミングで実行されます。
3.レンダリング
このフェーズでは
- スタイルの計算
- レイアウト
が行われます。
スタイルの計算
先ほど生成した、DOM と CSSOM を利用して、どのノードにどのようなスタイルが当たるのかを詳細度をもとに計算します。これが DOM の全てのノード対して行われます。
レイアウト
DOM 内のノードに当たるスタイルが計算された後、レンダリングエンジンはノードに対して視覚的なレイアウト情報の計算を行います。ここで言う視覚的なレイアウト情報というのは具体的には以下のようなものがあります。
- 要素の大きさ
- 要素のマージン
- 要素のパディング
- 要素の位置
- 要素の z 軸の位置
4.レンダリング結果の描画
ここでは
- グラフィックエンジンに向けた命令の作成
- 命令の実行
- レイヤーの合成
が行われます。
グラフィックエンジンに向けた命令の作成
ブラウザは内部に画面にピクセルを描画するためにグラフィックエンジンと呼ばれるソフトウェアを内蔵しています。このフェーズでは、このグラフィックエンジンに向けた『〇〇を描画しろ!』という命令を生成します。
命令の実行
このフェーズで実際にピクセルへと描画されます。この時レイヤーという単位で一枚一枚実行され、レイヤーは次のような条件がある際に複数生成されます。
- 要素が
position: abusoluteなスタイルプロパティが適用されている - 要素が
position: fixedなスタイルプロパティが適用されている - 要素が
transform: translate(0px, 0px, 0px)などの GPU で描画、合成される CSS プロパティを持っている - 要素に
opacityCSSプロパティが適用されており、透過して背後のコンテンツが表示される必要がある。
レイヤーという概念を導入することで、再レンダリング時に再利用して素早く再レンダリングすることができる場合があります。
レイヤーの合成
ここで先ほど生成されたレイヤーを合成し、最終的なレンダリング結果を生成し、描画します。
まとめ:monkey_face:
- リソースの読み込み
- ダウンロード
- 変換
- JavaScript 実行
- レンダリング
- スタイルの計算
- レイアウト
- レンダリング結果の描画
- グラフィックエンジンに向けた命令の作成
- 命令の実行
- レイヤーの合成
最後に
何か間違ってたり、おかしなことを言っていたら優しく教えていただけるとありがたいです。強く言われると普通に大きい声で泣きます。
では
Bye